Vielen Dank, dass Du an unserem Experiment teilgenommen hast. Ohne Deine Hilfe wäre unsere Forschung zu sprachlicher Kreativität nicht möglich.
Im Folgenden möchten wir Dich in die Hintergründe dieser Aufgabe einweihen. Die mittlerweile erstaunlichen Fähigkeiten von Künstlicher Intelligenz (KI) werden überall diskutiert, wie Diskussionen zu ChatGPT und den vielfältigen Einsatzgebieten von Chatbots belegen. Uns interessiert, in welchem Maß KI zu sprachlicher Kreativität fähig ist. Mit Euren Urteil können wir herausfinden, wo es noch erkennbare Unterschiede zwischen menschlicher und maschineller Textproduktion gibt. Bei unserem Mensch-Maschine Quiz handelt es sich um einen direkten Vergleich von Daten, die wir über das Internet mit menschlichen Teilnehmer*innen gesammelt haben mit solchen, die wir mit Hilfe von zwei sogenannten Large Language Models – GPT-2 und Chat-GPT – erstellt haben. Dabei haben wir sowohl Menschen als auch Sprachmodelle dieselben Satzanfänge fortsetzen lassen. GPT-2 ist ein älteres Sprachmodell aus dem Jahr 2019 und ist ein Vorläufer für Chat-GPT aus dem Jahr 2022. Während Fortsetzungen von GPT-2 im Vergleich zu menschlicher Sprache zum Teil noch gut als "künstlich" erkannt werden kann, ist mit ChatGPT ein System vorhanden, das viel "menschlicher" erscheinende Sätze produzieren kann.
Unsere Forschung zu Texten von Menschen und Maschinen
In unserer Forschung zu Large Language Models haben wir deutliche Unterschiede zwischen GPT-2 und von Menschen produziertem Text gefunden. In den Prompts machen wir von Impliziter Kausalität (nach der Satzverknüpfung weil) und Impliziter Konsequentialität (nach sodass) von psychologischen Verben wie faszinieren und bewundern Gebrauch. Diese Verben bilden ein gutes Vergleichspaar, weil die semantischen Rollen im durch das Verb beschriebenen Ereignis genau umgekehrt besetzt werden: im einen Fall bei faszinieren löst das Subjekt die Erfahrung im Objekt aus (wir sprechen von Stimulus-Experiencer Verben), im anderen Fall bei bewundern verhält es sich genau umgekehrt (Experiencer-Stimulus Verben). Die Beobachtung ist, dass je nach Verb und Satzverknüpfung bei Menschen klare Vorlieben bestehen, jeweils direkt mit einem Personalpronomen über das Subjekt (Maria) oder das Objekt (Peter) fortzusetzen. Die Schwierigkeit bei diesen Prompts besteht darin, dass sie sehr kurz sind und der Satz ohne Kontext erscheint. Hier sind Beispiele:
- Maria faszinierte Peter, weil ... (typischerweise Fortsetzung über Maria, z.B. weil sie so mutig war)
- Maria bewunderte Peter, weil ... (typischerweise Fortsetzung über Peter, z.B. weil er so diplomatisch war)
- Maria faszinierte Peter, sodass ... (typischerweise Fortsetzung über Peter, z.B. sodass er sie kontaktierte)
- Maria bewunderte Peter, sodass ... (typischerweise Fortsetzung über Maria, z.B. sodass sie von ihm schwärmte)
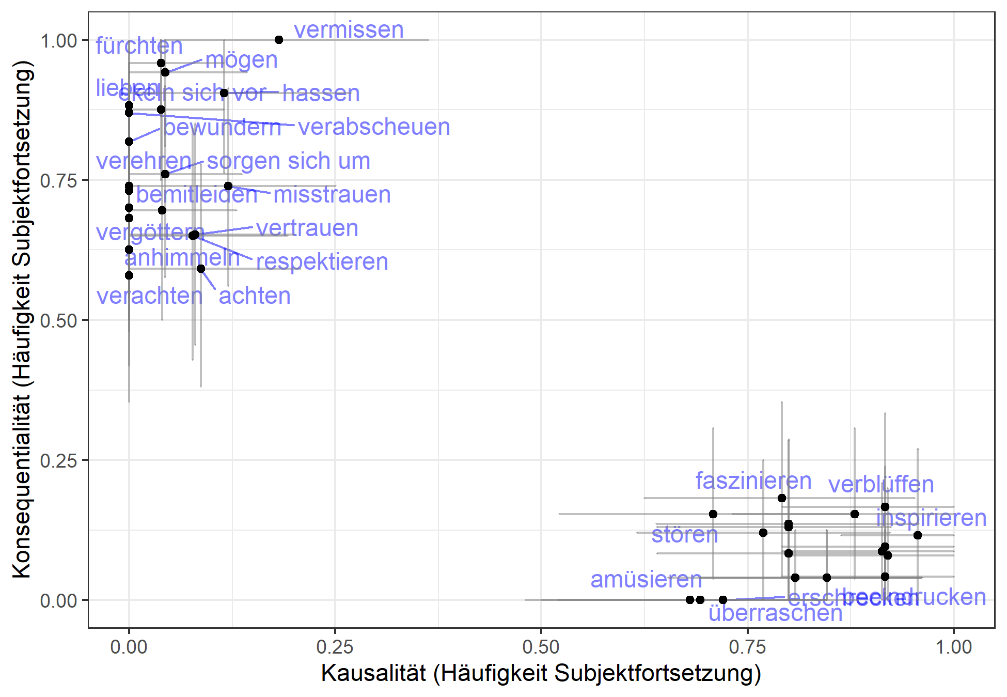 Für alle Verben, die wir getestet haben, siehst Du in der Grafik links dieses Muster klar in den menschlichen Daten. Diese stammt aus einem im letzten Jahr erschienen Artikel von Forschenden aus der Diskurswerkstatt (Solstad & Bott, 2022) und zeigt den relativen Anteil von Fortsetzungen mit Subjektbezug für die beiden Verbtypen, die zwei klar abgegrenzte Wolken bilden. Links oben finden wir die Experiencer-Stimulus Verben wie bewundern mit Objektbezügen bei Kausalität nach weil und Subjektbezügen nach sodass. Das exakt umgekehrte Muster beobachten wir bei Stimulus-Experiencer Verben wie faszinieren, die die Wolke rechts unten bilden. Die Striche nach oben und unten bzw. links und rechts stellen den statistischen Unsicherheitsbereich unserer durch das Experiment vorgenommenen Schätzung dar.
Für alle Verben, die wir getestet haben, siehst Du in der Grafik links dieses Muster klar in den menschlichen Daten. Diese stammt aus einem im letzten Jahr erschienen Artikel von Forschenden aus der Diskurswerkstatt (Solstad & Bott, 2022) und zeigt den relativen Anteil von Fortsetzungen mit Subjektbezug für die beiden Verbtypen, die zwei klar abgegrenzte Wolken bilden. Links oben finden wir die Experiencer-Stimulus Verben wie bewundern mit Objektbezügen bei Kausalität nach weil und Subjektbezügen nach sodass. Das exakt umgekehrte Muster beobachten wir bei Stimulus-Experiencer Verben wie faszinieren, die die Wolke rechts unten bilden. Die Striche nach oben und unten bzw. links und rechts stellen den statistischen Unsicherheitsbereich unserer durch das Experiment vorgenommenen Schätzung dar.
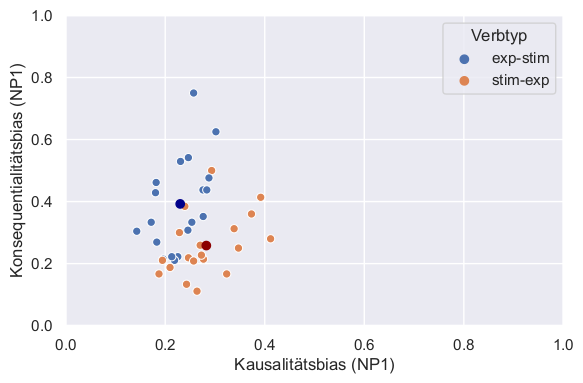 Für Fortsetzungen aus GPT-2 konnten wir dieses bei Menschen gefunden Muster in einer an der Universität Bielefeld entstandenen Bachelorarbeit (Kankowski, 2022) nicht reproduzieren, wie die Grafik rechts zeigt. GPT-2 setzte meistens über das Objekt fort mit nur kleinen Unterschieden zwischen den beiden Verbtypen und unabhängig davon, ob der Prompt mit weil oder sodass endete. Die mittleren Häufigkeiten für die Verbtypen sind in dem dunkelblauen und dunkelroten Punkt dargestellt. Auch in anderen Studien zeigten sich klare Unterschiede zwischen GPT-2 und menschlicher Sprache (hier eine weitere Arbeit aus der Diskurswerkstatt, Zarrieß, Gröner, Solstad & Bott, 2022).
Für Fortsetzungen aus GPT-2 konnten wir dieses bei Menschen gefunden Muster in einer an der Universität Bielefeld entstandenen Bachelorarbeit (Kankowski, 2022) nicht reproduzieren, wie die Grafik rechts zeigt. GPT-2 setzte meistens über das Objekt fort mit nur kleinen Unterschieden zwischen den beiden Verbtypen und unabhängig davon, ob der Prompt mit weil oder sodass endete. Die mittleren Häufigkeiten für die Verbtypen sind in dem dunkelblauen und dunkelroten Punkt dargestellt. Auch in anderen Studien zeigten sich klare Unterschiede zwischen GPT-2 und menschlicher Sprache (hier eine weitere Arbeit aus der Diskurswerkstatt, Zarrieß, Gröner, Solstad & Bott, 2022).
Bei Chat-GPT zeigen hingegen erste experimentelle Ergebnisse (Cai et al., preprint), dass die Unterschiede zwischen Mensch und Maschine bei diesem Phänomen zu verschwinden beginnen. Nun sind wir gespannt auf die Ergebnisse unseres Quiz, die uns zeigen, ob sich diese Unterschiede im produzierten Text auch bei der Beurteilung dieser Texte zeigen. Demnächst mehr dazu in unserem Blog.